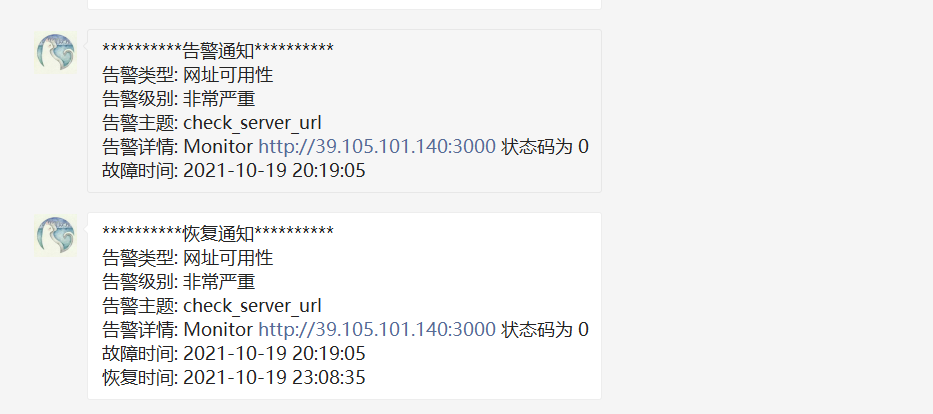
说明
在"部署案例"原配置进行修改
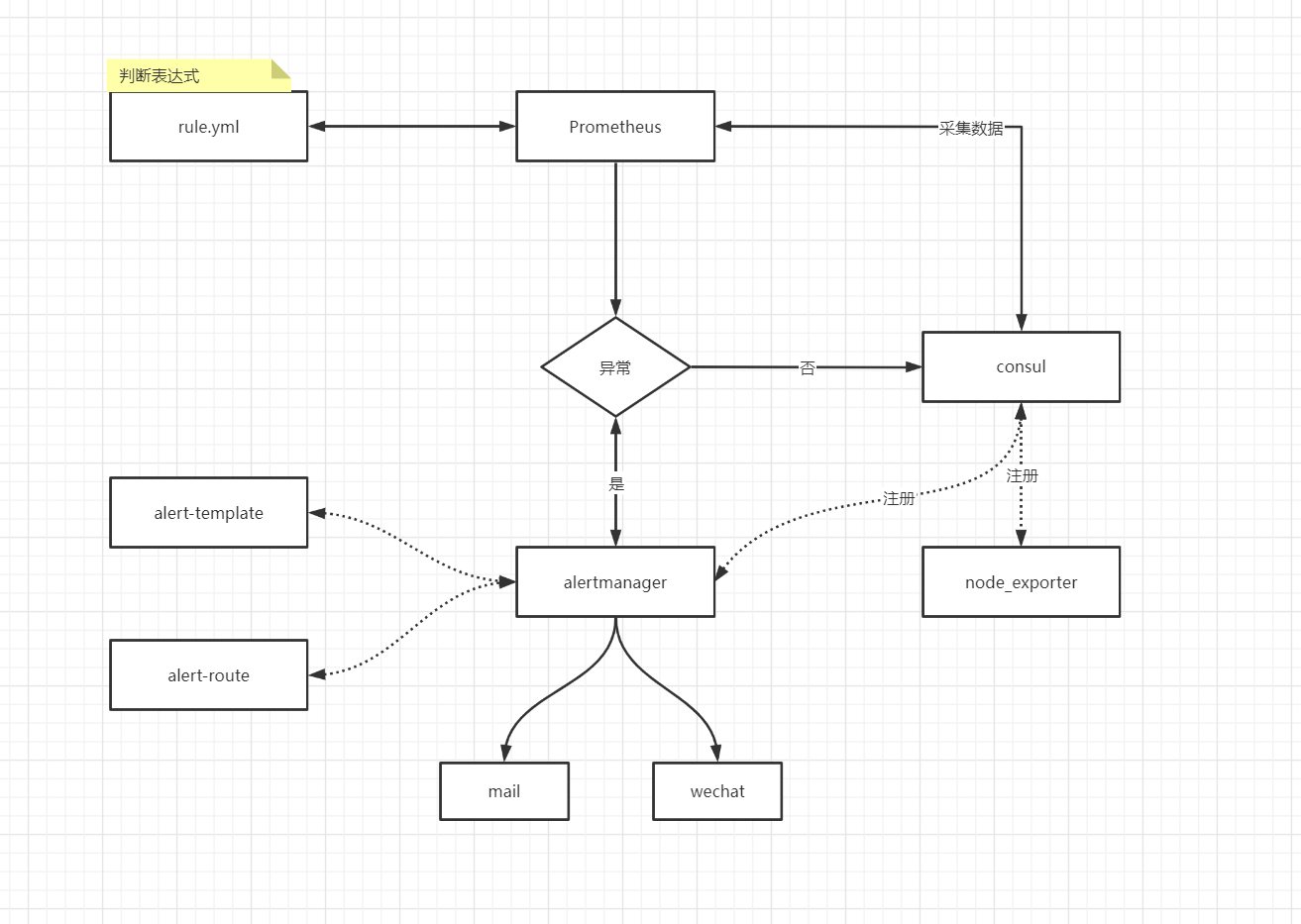
一. 流程图
二. alertmanager修改
2.1 新增告警内容模板
告警内容案例
pwd: /opt/app/monitor/alertmanager/wechat.tmpl
\{\{ define "wechat.default.message" \}\}
\{\{- if gt (len .Alerts.Firing) 0 -\}\}
\{\{ range .Alerts \}\}
**********告警通知**********
告警主题:\{\{ .Annotations.summary \}\}
告警等级:\{\{ .Labels.serverity \}\}
告警类型:\{\{ .Labels.alertname \}\}
告警内容:\{\{ .Annotations.description \}\}
故障时间:\{\{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" \}\}
\{\{- end \}\}
\{\{- end \}\}
\{\{- if gt (len .Alerts.Resolved) 0 -\}\}
\{\{ range .Alerts \}\}
**********恢复通知**********
告警主题:\{\{ .Annotations.summary \}\}
告警等级:\{\{ .Labels.serverity \}\}
告警类型:\{\{ .Labels.alertname \}\}
告警内容:\{\{ .Annotations.description \}\}
故障时间:\{\{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" \}\}
恢复时间:\{\{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" \}\}
\{\{- end \}\}
\{\{- end \}\}
\{\{- end \}\}
2.2 修改配置
相比于zabbix,不需要单独编写告警脚本
pwd: /opt/app/monitor/alertmanager/alertmanager.yml
global:
resolve_timeout: 1m // 持续多长时间未接收到告警后标记,告警状态为resolved
templates:
- "/opt/app/monitor/alertmanager/template/wechat.tmpl" // 告警内容模板
route:
group_by: ['alertname'] // 分组标签
group_wait: 30s // 告警等待时间。告警产生后等待5s,如果有同组的一起发出
group_interval: 1m // 两组告警的间隔时间
repeat_interval: 1m // 重复告警的间隔时间
receiver: wechat // 告警接收人
receivers:
- name: 'wechat' // 定义告警接收人
wechat_configs:
- corp_id: 'corp_id'
agent_id: 'agent_id'
api_secret: 'api_secret'
to_user: 'TianCiwang' // 接收者或者是用户或者是部门,选一个就行,to_party: ' PartyID1 | PartyID2 '
send_resolved: true // 恢复告警
三. prometheus
3.1 rules文件新增
环境监控
pwd:/opt/app/monitor/prometheus/rule/alert-environment.yml
groups:
- name: "alert-environment"
rules:
- alert: instance_memory_use
expr: (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 < 10
for: 1m
labels:
alertname: 服务器内存状态
serverity: 非常严重
annotations:
summary: "内存告警"
description: "\{\{ $labels.ip \}\} 可用内存 \{\{$value \| printf \"%.2f\" \}\}% < 20%"
- alert: instance_load5
expr: node_load5 > 30
for: 1m
labels:
alertname: 服务器负载
serverity: 非常严重
annotations:
summary: "服务器负载告警"
description: "\{\{ $labels.ip \}\} 服务器近5min负载为\{\{$value \| printf \"%.2f\" \}\}%,已超过30%"
应用监控
pwd:/opt/app/monitor/prometheus/rule/alert-module.yml
groups:
- name: "alert-module"
rules:
- alert: check_tcp_port
expr: check_server_port == 0
for: 1m
labels:
alertname: 端口状态
serverity: 非常严重
annotations:
summary: "内存告警"
description: "\{\{ $labels.ip \}\} 端口 \{\{ $labels.port \}\} 状态为 \{\{ $value \}\}"
业务监控
pwd:/opt/app/monitor/prometheus/rule/alert-server.yml
groups:
- name: "alert-server"
rules:
- alert: check_server_url
expr: check_server_url != 200
for: 1m
labels:
alertname: 服务站点
serverity: 非常严重
annotations:
summary: "网址可用性"
description: "\{\{ $labels.service \}\} \{\{ $labels.url \}\} 状态码为 \{\{ $value \}\}"
3.2 修改prometheus配置
pwd:/opt/app/monitor/prometheus/prometheus.yml
# 全局参数
global:
scrape_interval: 30s
scrape_timeout: 20s
evaluation_interval: 15s
alerting:
alertmanagers:
- follow_redirects: true
scheme: http
timeout: 10s
api_version: v2
consul_sd_configs:
- server: "172.17.235.140:8500"
relabel_configs:
- source_labels: [__meta_consul_tags]
regex: .*alertmanager.*
action: keep
- source_labels: [__meta_consul_service]
target_label: job
- action: labelmap
regex: __meta_consul_service_metadata_(.+)
rule_files:
- /opt/app/monitor/prometheus/rule/*.yml
scrape_configs:
- job_name: 'check_tcp_port'
static_configs:
- targets: ['172.17.235.140:8006']
- job_name: 'check_server_url'
static_configs:
- targets: ['172.17.235.140:8007']
- job_name: 'node-exporter'
consul_sd_configs:
- server: "172.17.235.140:8500"
relabel_configs:
- source_labels: [__meta_consul_tags]
regex: .*node_exporter.*
action: keep
- source_labels: [__meta_consul_service]
target_label: job
- action: labelmap
regex: __meta_consul_service_metadata_(.+)
四. 案例
停掉grafana
告警内容恢复内容一致,还需处理